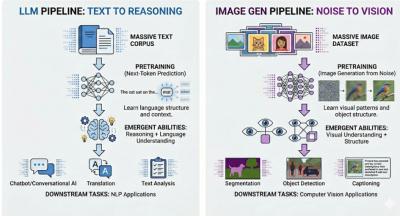
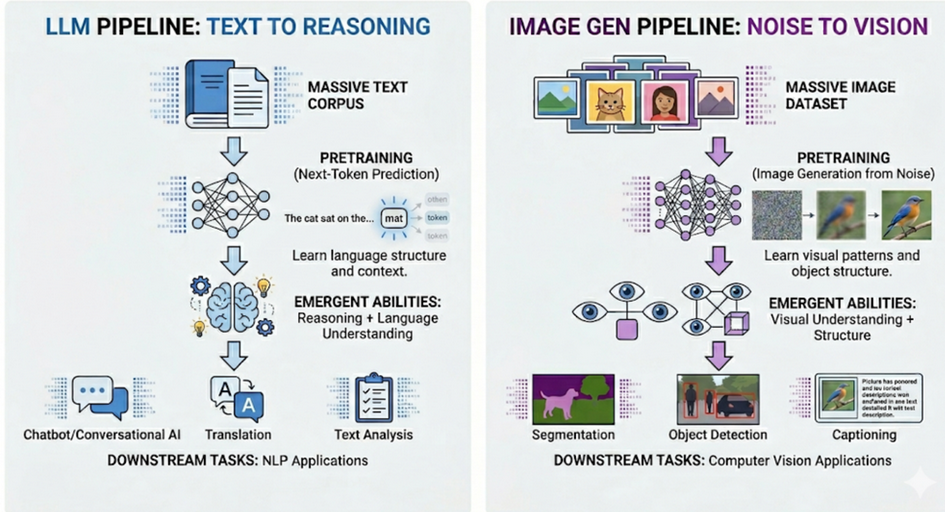
Vision Banana is "a unified model introduced by Google DeepMind that both generates RGB images and performs visual understanding tasks within a single architecture, controlled entirely through text prompts." Or in short: "image generators are generalist vision learners." It's interesting because it blends visual tasks and semantic tasks (eg., find all the cats' ears in the photo) in a single architecture. Just your regular reminder that AI is far more than large language models. (p.s. my take on the 'banana' name: it originates from the meme in image sites (like Imgur) of using a 'banana for scale').
Today: Total: [] [Share]



{kind=link}