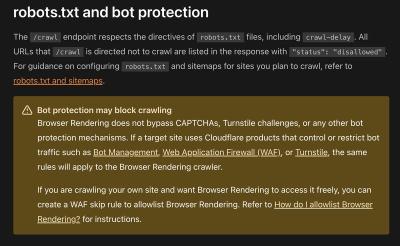
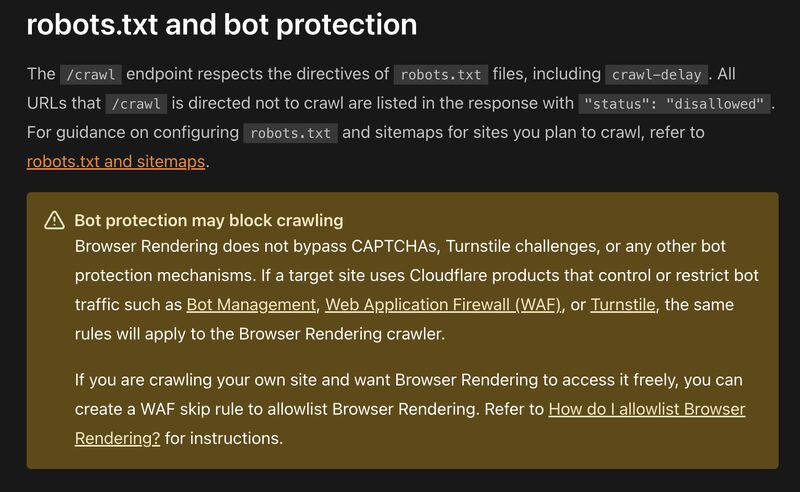
Cloudflare's announcement caused a stir in the socials today. "You can now crawl an entire website with a single API call using Browser Rendering's new /crawl endpoint, available in open beta. Submit a starting URL, and pages are automatically discovered, rendered in a headless browser, and returned in multiple formats, including HTML, Markdown, and structured JSON." To be clear, web scraping applications have been around for a long time (it was the first thing anyone wrote back in the 1990s!) with services like Firecrawl and Elastic (try). The issue is that Cloudflare has marketed itself as a service that prevents web scraping. Still, as Ian Kerins argues, the Cloudflare scraper "doesn't bypass anti-bot systems." However, "What this '/crawl' endpoint really is though, is another step in Cloudflare's broader push toward signed agents and a 'pay-to-crawl' internet."
Today: Total: [] [Share]



{kind=link}