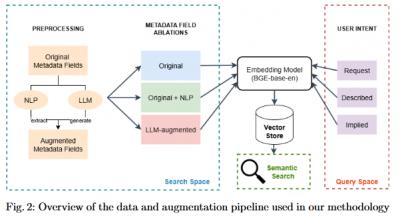
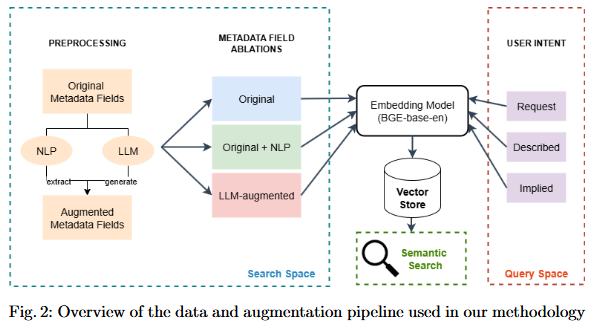
In the early days of learning resource metadata the idea was that users would conduct a faceted search for relevant results. This allowed users to filter or refine results by attributes, for example, date, author, category. The approach has its flaws, however. Often the metadata is incorrect, or if a restricted vocabulary is enforced, it isn't sufficiently expressive. Often, many of the metadata elements simply weren't used. This paper examines where a simple natural language 'description' field would enable a natural language search, and in particular, whether "dataset descriptions, especially those generated by large language models (could) play a critical role in enabling effective natural language querying for dataset search." The answer offered in this paper, not surprisingly, is that they could. From my own experience, I would suggest that there's a limitation, however - in my own dataset developed for OLDaily, my descriptions not only summarize articles, but offer context, opinions, associations and other information that helps me query my data (and might be useful for others as well), which AI-generated descriptions are unlikely to provide.
Today: Total: [] [Share]



{kind=link}