Mar 01, 2016
Abstract: This paper introduces the personal learning environment, as being developed in the National Research Council's Learning and Performance Support Systems program, as a means of deploying open educational resources to best advantage to support personal learning. Our experience with the aggregation, deconstruction, and representation of open learning resources has reinforced to us the understanding that course contents should be understood as a network of inter-related objects, which we have chosen to represent in a graph database. Moreover, the prevalence of non-textual and indeed non-representational conversational objects leads us to interpret knowledge as a subsymbolic network of microcontents. Learning and performance support, in other words, should be seen as more than the provision of factual representations or pages from a reference manual. It should speak to the personal hands-on experience of performing a task, presented in a manner as close as possible to the original experience.
Keywords: Learning, training, education, analytics, personal learning environment, personal learning record, open education, open educational resources
Introduction to the LPSS Program
In 2014 the senior executive committee of Canada's National Research Council endorsed a proposal to establish a research program called 'Learning and Performance Support Systems'. The purpose of this research program was to address the skills challenge in Canada's economy by developing the next generation of educational technology.
This technology, known generically as a 'personal learning environment' (PLE), is based on a concept that has been current in the education technology literature for approximately ten years but which has as yet been unrealized. It is centred around the challenging concept that each person could have his or her own personal learning management system.
The end goal of the LPSS program is to deliver software algorithms and prototypes that enable the training and development sector to offer learning solutions to industry partners that will address their immediate and long term skills challenges. In the short term, LPSS will respond to the immediate needs of industry with existing tools and technologies on a research contract or fee-for-service basis. In the long term, working with strategic industry partners, LPSS will develop a learning and performance support infrastructure that will host and deliver the following key services:
- learning services and a resource marketplace, providing content and service producers with unfettered access to customers, and employees (and prospective employees) with training and development opportunities;
- automated competency development and recognition algorithms that analyze workflows and job skills and develop training programs to help employees train for specific positions;
- a personal learning management tool that will manage a person's learning and training records and credentials over a lifetime, making it easier for employers to identify qualified candidates and for prospective employees to identify skills gaps;
- and a personal learning assistant that enables a student or employee to view, update and access training and development resources whether at home or on the job, at any time.
The LPSS infrastructure includes underlying technologies to support these services, including identity and authentication services, cloud access and storage challenges, personal records and credentials, document analysis and analytics, and interfaces to third-party services such as simulation engines and other advanced training support services.
Like the Massive Open Online Course (MOOC) which precedes it, LPSS is designed to take advantage of a network of open education resources and learning services. This paper describes the theory and mechanisms behind the development of this technology.
OERs as words in a Conversation
Think of open educational resources not as texts and lessons and such, but as words in a conversation.
Why think of them this way? In part, it's because that's how they're used. But more importantly, it forces us to think about how they can be used.
Consider how words (the traditional kind, made up of letters and arranged in sentences) are used in education. A lecture, for example, is composed of words, a 10,000 word presentation in 55 minutes. They are defined, used to describe phenomena, to explain causes, to argue in support of conclusions. They are the tools of teaching.
If we think of these words as educational resources, then what we can do with them is sharply limited. We are constrained in so many ways:
- The words have to follow from, and feed into, learning objectives and educational purpose
- The words have to contain educational content, namely, facts, theories and principles that students are expected to learn
- The words have to be organized to pedagogical purpose, that is, performing (say) one of Gagne's tasks of gaining attention, providing feedback, assessing performance, etc.(Gagné, Briggs, & Wager, 1992)
- That pedagogy is limited to one of knowledge transfer from authority to non-authority
- Students, with the exception of responding to predefined questions, are rendered essentially mute
That was the actual state of affairs in the classroom until recent decades. But through advances such as active learning, problem based learning, constructivism, and other new educational approaches, words in the classroom have been liberated.
Examples could be multiplied almost without end, but a typical case may be made using Gordon Pask's conversational theory (CT) of learning. (Roschellel & Teasley, 1995) Using interrogation, the students can ask how a process takes place, request an explanation of why a process takes place, and inquire about the how and why of the topic itself, in the wider context of the subject and the material covered in the class.
And from this recognition that students can speak it's a small leap from students conversing with teachers to students conversing with each other. This forms the basis of now well-established approaches such as social constructivism, team learning, collaboration and project-building (there is some great literature on the idea of mathematics and scientific discovery as conversation (Ernest, 1993)) ranging from Vygotsky to Wenger. (Warmoth, 2000) The understanding here is that knowledge is reified by, and is the product of, not only an individual, but also of the wider community. (Hildreth & Kimble, 2002) (Stewart, 2015)
We treat open educational resources, however, very differently. People focus on the distribution and the licensing of OERs, but few people spend any time on the latter half of the UNESCO definition: "OERs range from textbooks to curricula, syllabi, lecture notes, assignments, tests, projects, audio, video and animation." (UNESCO, 2013) This definition limits us in the same ways we were limited with educational words, above. And in particular, pedagogy is limited to knowledge transfer and students are rendered mute.
There are the following major areas of :
- In order to understand what can be said, it is useful to deconstruct OERs and examine what sort of inferences or learning can be drawn from them
- In order to understand what new knowledge can becreated, it is useful to understand how to describe knowledge and representation
- And from this, we can form an understanding of how, and why, students can be the primary authors of OERs
This will form the remainder of the theoretical structure of this paper, and in the process of this discussion, we will examine some major elements of a personal learning environment, and then close with some case studies of preliminary work exploring this approach.
Deconstructing OERs
So if we are to consider OERs to be like words in a conversation, what does this entail for our understanding of OERs?
When we analyze a sentence, as in for example a typical Chomsky phrase-structure grammar, we can observe a base structure of noun-verb-object (See Figure 1), but in addition, so much more, including quantification, inference, causality, preposition, modality, and more. We also see additional factors, such as vagueness and ambiguity, context-sensitivity, idiom and metaphor, and ultimately, a rich conceptual environment populated with people, things, ideas and most everything else. (Milekic & Weisler) 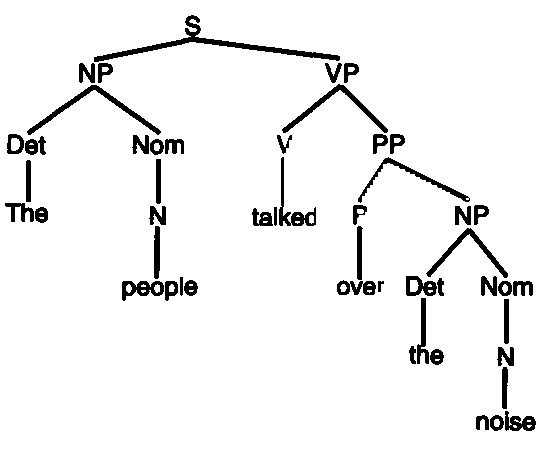
Figure 1: Noun-verb-object
An analysis of social media takes this a step further, as social media exists in a rich community context where messages may be geographically based, address topics, belong to threads, be replies to other messages, and otherwise be woven into a wider fabric of conversation, traces of which may remain in the media. A good example of this is the metadata provided in the common Tweet. In addition to the sender's name and nickname we may have information about the conversation, an embedded image, a hashtag, embedded URLs or references to other people, geotags, time stamps, and more. (Allen, 2014) (See Figure 2)
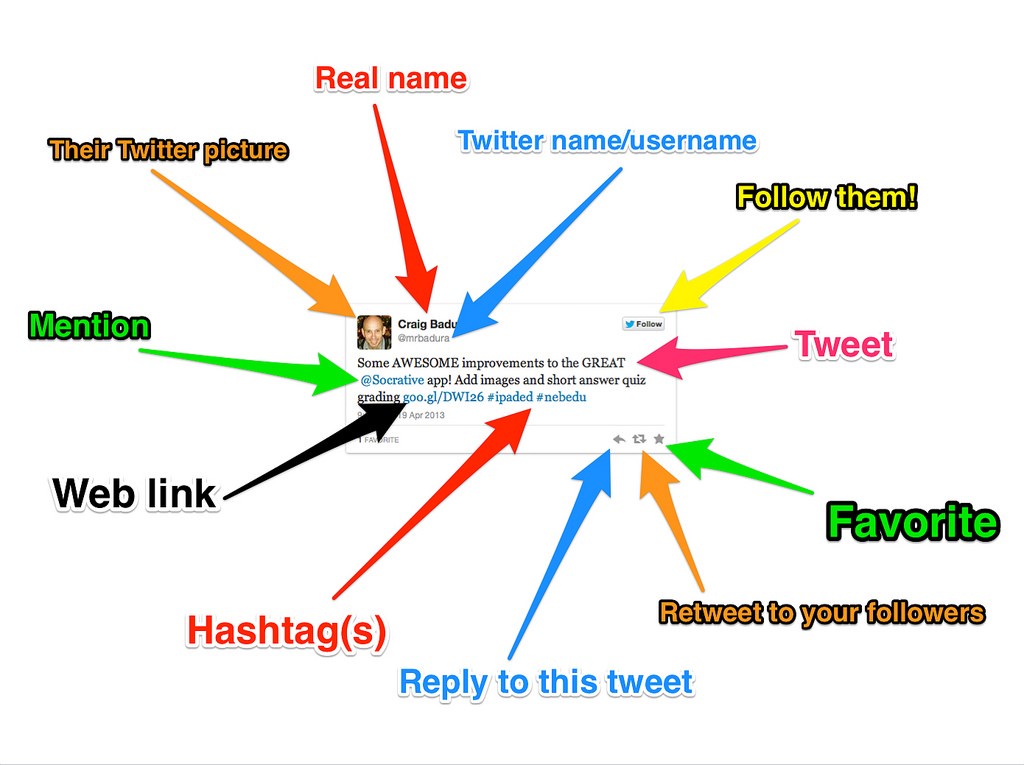
Figure 2: Anatomy of a Tweet
It is important to understand that when a person who lives in a rich information environment receives communications absent these contextual cues, the content is not merely viewed as abstract and empty, it is viewed as irrelevant, a form of non-communication. The reason for this is that there is limited mechanisms available to comprehend this communication as a part of overall knowledge.
In any case, and additionally, a communication in a multimedia environment may contain in addition multiple layers of meaning (the term 'layers' is probably misapplied, but will suffice to make the point). We see this in the case of the LOLcat or the internet meme, which typically juxtaposes three essential elements:
- An image, either of a cat or a popular or iconic figure, or of something else easily recognized (often these pictures will be in prototypical poses, such as 'facepalm')
- A sentence or phrase either expressing a sentiment of referring to some recent event (again often in a prototypical format, such as kitty pidgin)
- A social, cultural and communicative context in which this all makes sense. (Dash, 2007)(McCulloch, 2014)
These aspects of an online communication are understood as well, or as intuitively, as more traditional aspects of communication (such as the ones we have just explored). Like traditional forms of communication, they are not understood. For those who are literate, however, understanding is instant and expert.
Additionally, because it is a conversation, it is unfocused and unrestricted. People say what they want to say on the internet despite the efforts of list managers hoping to keep comments "on topic" (Audacity, 2015), and if they cannot say it in one forum, they take it to another. And even though services like Twitter, Facebook and Google seem to want to consolidate all social network activity within a single service, there is no 'one' place conversation takes place online. Conversations can happen in many for a, employing many hosts, and the same conversation may jump from Facebook to Google to email without losing coherence.
From the perspective of educational technology, these observations force a rethinking of the design and distribution of OERs. Users will look for a context (and may place it incorrectly absent an obvious location). They will be looking for meaning and reference not only in the academic domain, but also from their social and cultural milieu. A message is not located simply within a single physical environment, but also within a wider set of interactions among a community employing many social network services.
In the LPSS Program (National Research Council Canada, 2015), we approach these issues with a set of technologies creating what we call the 'Resource Repository Network' (RRN). The RRN has two major tasks, one obvious the other less obvious:
- To discover and recommend content relevant to the user's interests, retrieving it from one of many remote locations, and storing either the metadata or the artifact itself in a location accessible to the user in the future, and
- To assist the user in understanding the context, relevance and significance of the remote resource
Traditional approaches to OERs have focused on the creation and sustainability of OER 'repositories', without a lot of attention paid to how students access these resources and use them (probably mostly because the primary users of OER repositories are thought to be academic institutions and teachers).
An effective RRN, however, needs over time to (if you will) paint a picture of the user's social, academic and professional landscape. In RRN, we employ the mechanism of a 'source manager' containing the internet address and access credentials for a range of remote resource repositories. But because we view OERs as words in a conversation, we aggregate resources from wherever a conversation may occur:
- Social media such as Twitter, Facebook, LinkedIn, Google, etc
- Personal communications tools such as email and instant messaging
- Enterprise tools such as Sharepoint, Wiki or shared directories
- Websites, RSS feeds, OAI repositories, Flickr, YouTube, TED, iTunes
- Learning management systems, MOOCs, and other institutional sources
This list could be expanded almost indefinitely. It signifies that the sources of learning on the internet are not limited to academic institutions and online courses, but rather, extend far wider than these traditional resource repositories.
The second part of the RRN is the analysis on the incoming resources. Learners, especially novice learners, may not be able to comprehend the meaning and significance of resources, especially when there are a large number of resources, as in many cases of online learning. This has been commented upon by numerous critics. (Herr, 2007) In traditional education, this mediating voice is provided by the instructor, however, in a conversation, no such mediating voice exists, and a participant must gradually become a knowing member of the community through practice and feedback.
Analysis can be grouped into two major tasks, which can be classed as 'structural' and 'semantic':
- In structural analysis, we identify and extract the constituent entities referenced in the communication, as for example in the linguistic analysis or tweet analysis, identifying events, people, places, relations, and the like
- In semantic analysis, we attempt to comprehend the meaning of the communication in context, identifying metaphors and hidden meanings, sentiments, gists, inferences and connotations, and the like
LPSS's RRN currently performs elements of the first sort of analysis and will, by employing National Research Council programs such as text analytics (National Research Council Canada, 2015), sentiment analysis (Mohammad, Kiritchenko, & Zhu, 2013) and automatic translation, also develop mechanisms for the second.
In an ongoing (and probably never-ending) development process, RRN will assemble a set of components that analyze online communications sent to an individual, and then from the person's individual perspective, analyze and comprehend the types of entities referenced and the relations that hold between them (See Figure 3).
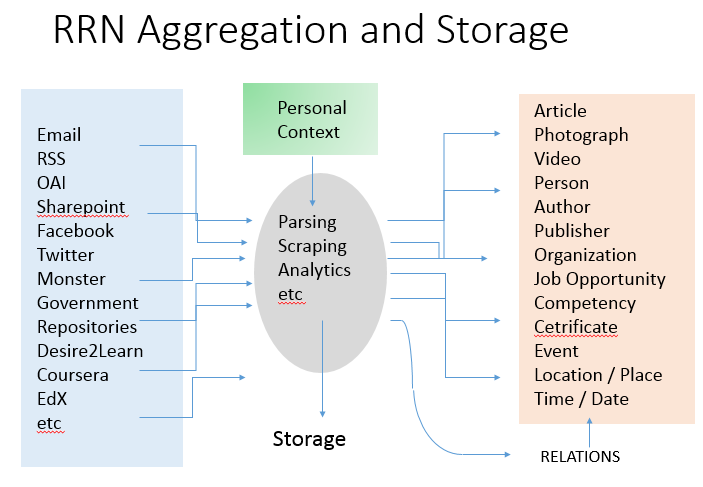
Figure 3. Resource Repository Network
Representing Knowledge
In the traditional model of the open educational resource as "textbooks to curricula, syllabi, lecture notes, assignments, tests, projects, audio, video and animation" it is difficult to think of an individual's knowledge and understanding from any other perspective than that Friere called the "Banking" model of learning. Education "becomes an act of depositing, in which the students are the depositories and the teacher is the depositor. Instead of communicating, the teacher issues communiques and makes deposits which the students patiently receive, memorize, and repeat." (Freire, 1993) That is, the teacher simply sends information to the student, which the student is responsible for remembering and repeating back when required.
The major criticism of the banking model is that students cannot learn anything over and above what was taught. They cannot adapt the knowledge to their own context, they cannot understand the terms in their own way, and as Friere would argue, they are ultimately disempowered and oppressed by education, rather than liberated. "The banking approach to adult education, for example, will never propose to students that they critically consider reality… The "humanism" of the banking approach masks the effort to turn women and men into automatons — the very negation of their ontological vocation to be more fully human." (Freire, 1993)
More serious, however, is the picture of knowledge that results from a model of education based on the transmission of information. As the 'banking' metaphor suggests, this is a model based on an accumulation of facts – a person's knowledge, in essence, could be reduced to an indefinitely long series of propositions (necessarily including rules and principles, because otherwise the complex and unplanned behaviours a person can undertake would be impossible).
Computationally, this is known as the physical symbol system hypothesis (PSSH), and it means that human understanding can be thought of literally as the manipulation of sentences and symbols, like a computer program. (Nilsson, 2007) This perspective permeates educational theory today, and the pedagogy of open educational resources as carriers of (propositional) learning permeates our discussions and assumptions in the field (think of how often terms like 'processing' and 'storage' and 'working memory' are used).
This approach additionally characterizes the management of open educational resources and learning resources generally. The very best an individual student is allowed is to have a 'course library' or 'publications library'. There is no sense that they would do anything more complex with them than to read them, remember them, and maybe store them.
We view knowledge differently, and this difference extends to the core of LPSS design. While objects and artifacts may be stored off to the side in a library, the core of LPSS takes the entities identified by RRN and stores the references to them in a graph database. (Neo4J, 2015) (Marzi, 2012) There are various graph database engines available, though we have been building our own in order to understand the functionality we require.
What is a graph database? "A graph database stores connections as first class citizens, readily available for any "join-like" navigation operation. Accessing those already persistent connections is an efficient, constant-time operation and allows you to quickly traverse millions of connections per second per core."(Neo4J, 2015) That is, the graph database is focused on representing the connections between entities more than the entities themselves. This enables the database to conduct searches using these connections far more efficiently than traditional table-based databases.
There are many reasons (Hogg, 2013) to represent an individual's data in a graph database. Here are a couple:
- A graph database does not require predefined entities. This means we do not have to know in advance everything a student is going to need; we add entities, properties and relations as they are encountered.
- A graph database supports distributed representation. What that means is that a concept is not represented as a series of self-contained sentences, but rather, as a set of connections throughout the graph.
- A graph database recognizes context and connections. What someone knows about plaster might influence their thoughts about European cities. In a graph database, concepts like 'plaster' and 'cities' overlap, and an event changing the state of one, also changes the state of another
- A graph database can be deeply personal. Each person experiences a unique set of entities and relations between them; though the symbols and images representing concepts may be used in common with other people, a graph database embodies the fact that each person's understanding of these is individual
In LPSS, each person has their own graph database containing all the entities and relations they have encountered over a lifetime of learning. The graph database contains references to analyses of the open educational resources they have encountered, but also any other content related to their learning and development. Each person's graph is individual, personal and private, just like their own thoughts and ideas.
Understanding the use of the OER in this way changes how we think about OERs – and educational resources generally – as resources in the support of learning. As currently conceived, each OER forms a part of a narrative structure, the sum total of which constitutes the content required to learn a discipline or skill. The 'quality' of a resource is related to how well it presents that educational content and how reliably it stimulates the memory of relevant facts or procedures, or competency in a given technique or skill.
A typical list of quality metrics (these can become complex and detailed) is offered by The JISC Open Educational Resources Guide (JISC, 2014): "The quality of learning resources is usually determined using the following lenses:
- Accuracy
- Reputation of author/institution
- Standard of technical production
- Accessibility
- Fitness for purpose."
The difficulty of such a quality metric is that none of these can be determined independently. 'Reputation', for example, is a standard that varies from place to place, person to person. 'Technical production' will be influenced not only by tastes and preference but also by accessibility requirements. We cannot generate a 'score' or a 'value' for any of these parameters without calculating the dependence of these paramaters on other factors.
Indeed, it is arguable that it is impossible to determine a priori whether a resource is 'quality' or not (though perhaps with decades of experience we may eventually draw some inferences). Ultimately, with Mill, we have to say, "The only proof capable of being given that an object is visible, is that people actually see it. The only proof that a sound is audible, is that people hear it: and so of the other sources of our experience. In like manner, I apprehend, the sole evidence it is possible to produce that anything is desirable, is that people do actually desire it." (Mill, 1879)
Authoring OERs
In a paper I presented (Downes, 2006) to the OECD a decade ago on sustainability models for open educational resources I argued that the only sustainable model for OERs was to have then created and consumed by the same people, the students themselves.
"OERs may be supported using what might be called a co-producer model, where the consumers of the resources take an active hand in their production. Such an approach is more likely to depend on decentralized management (if it is managed at all), may involve numerous partnerships, and may involve volunteer contributors." (Downes, 2006)
In traditional education the typical approach to learning is to stop other activities, to go to a classroom or learning centre, to focus on learning a specific body of content, and then return to one's ordinary life some days or some years later.
In LPSS we have focused on this as an undesirable and overly expensive approach to learning, and as the name of the program – "learning and performance support systems" – suggests, prefer to relocate the context of learning to authentic environments in which a person is attempting to meet some objective or complete a task (indeed, as Jay Cross says, "informal learning occurs when knowledge or a skill is needed in order to execute or perform a task. This means that the commitment of the learner is at the highest possible level as it is the inner drive that initiates the learning process. Also, learning takes place in connection to a specific situation or task." (Malamed, 2010))
What we find when we approach learning this way is that a person's 'learning environment' extends to include a wider social network or community. This is the source of Etienne Wenger's 'communities of practice', referenced earlier. (Wenger-Trayner, 2015) In almost any domain one cares to consider, there is an active and engaged network of interested people exchanging information and resources on the internet.
These are the real open educational resources. These are the source of what is probably most learning in the world (it would be interesting to see a study evaluating the scale and pervasiveness of unauthoritative learning resources and support). Even some of the projects which have become paradigms of the open education movement, such as Khan Academy, began life this way. (Noer, 2012)
The development of performance support resources (PSRs) is not the same as the development of formal learning resources. Because these are accessed at the point of need, PSRs need to be convenient, user-friendly and relevant. (Xin, 2014) This means many of the traditional stages of a learning event – gaining attention, assessment, etc. – are often absent. A person needing performance support will attend to the learning for only a short time, preferring to apply what was found immediately and to get back on task.
Performance support at the point of need is one stage in what can be described as a four stage process. In this process, the objective is not to provide the student with a body of knowledge to remember, but rather, to maximize the effectiveness of the performance support when it is needed. The steps (from Marty Rosenheck) are as follows (Rosenheck, 2012):
- Scenario-based learning – models and practice in simulations – long before the performance of a task
- Planning, refreshing, running through demonstrations – right before the performance
- Decision and activity support – during the performance
- Action review and reflection –after the performance
In the case of personal learning, the resources produced in the fourth step feed back into the first three steps. Two key activities take place (with respect to the resources) at this step. First, the resources that were used to prepare for performance support are reviewed, and either endorsed or critiques. Second, the process of review and reflection results in the creation of new resources which feed back into the performance support system. Rosenheck diagrams the process as follows (See Figure 4):
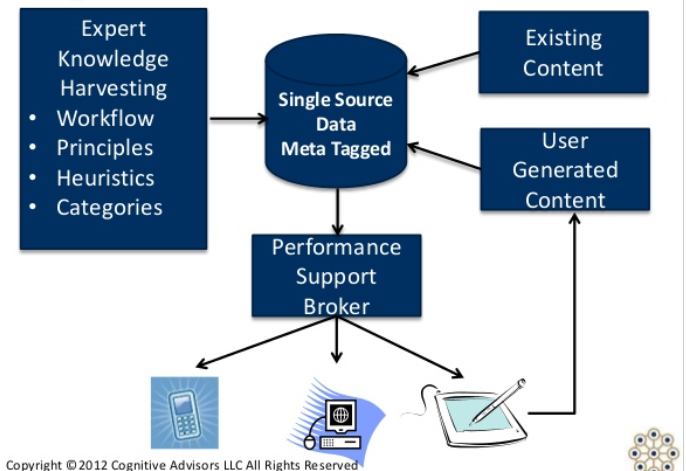
Figure 4. Production of user-generated content
In a production and learning environment, the concept is sometimes referred to as 'working openly' or 'working out loud'. John Stepper writes, "Working Out Loud starts with making your work visible in such a way that it might help others. When you do that – when you work in a more open, connected way – you can build a purposeful network that makes you more effective and provides access to more opportunities." (Stepper, 2014)
In the design of learning and performance support the bulk of attention is paid to providing access to resources and presenting them in multiple media at the point of need. Consequently, processes involving recommendation and selection dominate the literature. In the design of learning object technology, for example, the emphasis was on discovery and reuse. (Downes, 2001) In LPSS, the selection and recommendation of learning resources takes place through the process of manipulating the graph representation. But this is only one small part of a much more complex process.
The Advanced Distributed Learning PAL project (United States: Department of the Army, 2015) makes clear the constituent elements of an effective recommendation system. They are asking for the following:
- customized content, a transparent user interface, persistent internet access
- tracking learner experiences, adapting content, and integrating social media
- knowledge and information capable of being shared across the environment
- user's profile, learning attributes, and competencies to provide a tailored, personalized experience
- integrated with the physical world into a mixed reality learning suite
- design and assessment principles for the next-generation learner
From this description it is evident that the point-of-need learning support is engaged as much in the collecting of information as it is in the dissemination of information. (Regan, 2013) This collection of information is vital both to provide raw materials for the recommendation of learning resources, and also to support the creation of new learning resources.
Accordingly, in LPSS two major components are employed in order to support the reuse and generation of educational resources.
The first is the Personal Learning Record (PLR), which gathers information and provides a unique personal storage of the following:
- activity logs, created through interactions with external resources, stored as elements of the graph database, and imported and exported from external systems using a subject-verb-object language like xAPI
- a personal portfolio of works and artifacts; these are created by the user in the course of work and learning experiences, and include everything from papers and texts, artwork, videos and recordings of performance, messages and communications, and more
- a collection of certificates and achievements, including for example the person's collection of badges awarded by svarious systems, certificates and credentials verified or authenticated by third party agencies, records of courses completed and challenges achieved
The production of open educational resources is therefore enabled as a part of learning assistance provided at point of need, and the authoring typically takes place during the action review and reflection stage. This stage is probably one of the more important learning interventions a learning support system can make, because it is the reflection on practice that creates feedback mechanisms. (Jackson, 2004)
In the informal learning ecosystem, it is these post-learning and post-practice reflections that form the bulk of online learning content – the vast underground repository of open educational resources untapped (and unmentioned) in traditional OER discussions. One example from the world of computer programming is Stack Overflow, which provides point-of-need advice on methods and algorithms. Another important (and often maligned) resource is WebMD. In another domain is the 'Ask the Builder' website. Artists turn to sites like Deviant Art to create and share their experiences. There's even Vegan Black Metal Chef.
The LPSS Personal Learning Assistant is being designed with what we call an LPSS Toolkit in order to promote the capturing of learning experiences. Currently the tool supports the creation and publication of annotations and short notes. Composition takes place inside a single standard interface, and is published through any of a number of supported social media platforms. As is the case with harvesting, the development of PLA's capturing and publishing tools is an ongoing and probably indefinite process.
One of the benefits of employing a personal and distributed learning support system is that the learner is no longer limited to the specific learning management system. This not only supports open publishing, which is necessary in order to create an ecosystem of learning support resources, it also enables the production of these resources from external learning systems and actual workplace environments. The gaming industry provides an example of this, where recording and rebroadcasting in-game events, either live or as videos, has become a popular and widespread activity. (Casti, 2013) We also see this practice increasingly being employed in high-tech hands-on fields such as medicine. (Kondo & Zomer, 2014) It is important, from the perspective of promoting a system of open educational resources, that these types of activities be extended to include other domains, and that tools, support and assistance for the capturing of these experiences be developed.
As more and more personal experiences are recorded live, the need for a personal system to record and save these events becomes apparent. Numerous ethical and personal considerations exist. (Ornstein, 2015) Existing open education systems such as MOOCs and other online learning and social networking systems harvest personal data for demographic and marketing purposes. (Leskovec, Rajaraman, & Ullman, 2015) As these events become more personal, the need for personal ownership of resources becomes apparent, with sharing encouraged, but only with appropriate permissions and licenses similar to those employed by, for example, Creative Commons.
Case Studies
Massive Open Online Course – LPSS staff developed and researched the world's first Massive Open Online Courses, beginning with Connectivism and Connective Knowledge in 2008. It was the first to incorporate open learning with distributed content, making it the first true MOOC. It attracted 2200 participants worldwide, 170 of whom participated by creating their own blogs and learning resources, which were harvested by the course aggregator, gRSShopper.
As I wrote when summarizing this course, "What this means is that course content is not located in one place, but may be located anywhere on the web. The course therefore consists of sets of connections linking the content together into a single network. Participants in the course were encouraged to develop their own online presence in order to add to this distributed resource network. The course authors then used a content aggregation tool in order to bring all the content in one place." (Downes, 2011)
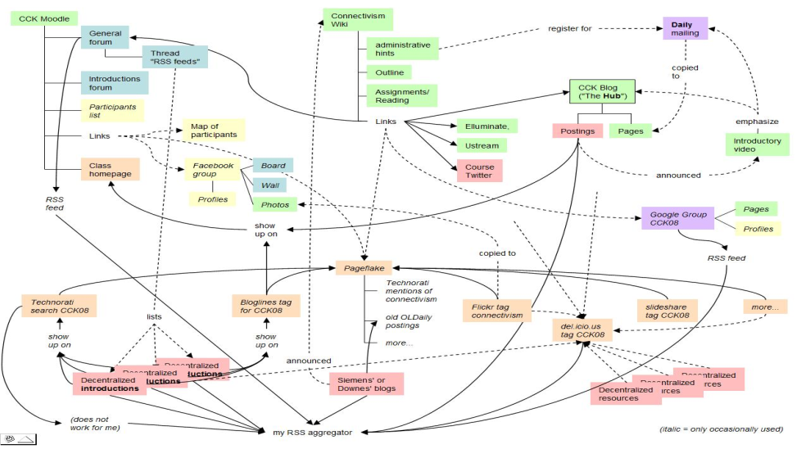
Figure 5. The distributed organization of a MOOC. Image by Matthias Melcher, 2008. (Melcher, 2008)
As the diagram (figure 5) depicts, the contents of the MOOC are not located in a single site, but rather are distributed across a number of services, such as Technorati, Blogger, Google Groups, Flickr, and others. This enables participants to create their own content and to contribute it to the course, and greatly facilitates the discovery and inclusion of open educational resources o the course. It is not necessary to import these resources to the course; rather, course authors and participants offered links to resources, and participants accessed them from their site of origin.
Plearn – During the early run of MOOCs the National Research Council was engaged in an internal project called Plearn, which was a prototype personal learning environment. This work combined an analysis of the MOOC experience, much of which was published by Helene Fournier and Rita Kop. (Kop & Fournier, 2011) In Plearn the aggregator developed for the MOOC project was adapted for personal learning, personal learning databases were created, and mechanisms for interacting with learning resources and publishing to a network were explored.

Figure 6. Plearn screenshot. (Kop & Fournier, 2011)
As can be seen from the screen shot (figure 6, above), the objective of Plearn was to integrate the distributed resource network, authoring functions, and social network into a single platform. It explicitly embodied the idea that taking a course required not just the consumption of open educational resources, but also the production of them.
The Plearn project made it clear that traditional database technology would be insufficient for the processes described here. The system performed too slowly to be of use in typical educational contexts. This was especially the case when working with unstructured data where properties were assigned to objects as field-value pairs, rather than as data elements in a table column.
OIF MOOC-REL – The Organisation international de la francophonie (OIF) is an international body of French-language nations promoting the educational, scientific and cultural aspects of the French language. As such, many of its member states are in Saharan and sub-Saharan Africa, where access to education is a significant issue. At a meeting in Moncton, Canada, in 2013 (Downes, 2013), the OIF made the decision to address issues of access through the production of open educational resources, and to that end, commissioned a MOOC jointly created by the Université de Moncton and the National Research Council.
The course was offered over ten weeks between March and May, 2014. Content and a distributed mailing list were managed by gRSShopper, a MOOC management system developed by NRC. The course was also followed by 280 people on Facebook. All contents were freely distributed under a Creative Commons license, promoting reuse of the materials even where direct online access to the course was not available. The results were sufficiently encouraging to allow the OIF to consider a follow-up for 2016.
Privy Council Office Badges for Learning – the concept of the digital 'badge' was introduced by Mozilla in order to provide a fine-grained mechanism for recognition of learning and achievements. The badge program uses a shared technical standard to support the display of badges in online environments, such as Mozilla's 'Backpack'. They may be issued by anyone, and can also be viewed on social network and blog sites.
In order to improve the recognition of informal learning in the public sector, the Canadian Privy Council Office established a badge-issuing system using Moodle and Mahara. In a secure environment, however, there was no mechanism to display the badges in a public setting. Using techn ology designed to support the use of learning services both inside and outside a secure environment, the NRC developed a system that allowed badges earned inside a secure environment to be safely displayed outside that environment.
Conclusion
This paper introduced the personal learning environment, as being developed in the National Research Council's Learning and Performance Support Systems program, as a means of deploying open educational resources to best advantage to support personal learning. When deployed as objects to be found, shared and manipulated by an interconnected network of course participants, these learning resources become more than educational materials for study and consumption. They become conversational objects, analogous to works in a sentence, exchanged among participants as they create a common community and context in which these objects acquire a more specific and localized meaning.
An understanding of an open educational resource, therefore, extends beyond an understanding of the content of the resource. Just as Chomsky showed the relation between different parts of a sentence, or Twitter metadata shows the constituent data relevant to a Tweet, the structure of a learning object is a combination of text and media elements, uses and re-uses, and contexts of deployment. For example, it becomes as important to know who shared a resource, in what course it was shared, and what it was shared with, in order to understand the role the resource plays in the course.
Our experience with the aggregation, deconstruction, and representation of open learning resources has reinforced to us the understanding that course contents should be understood as a network of inter-related objects, which we have chosen to represent in a graph database. Moreover, the prevalence of non-textual and indeed non-representational conversational objects leads us to interpret knowledge not as an instantiation of a physical symbol system, but rather a subsymbolic network of microcontents. Learning and performance support, in other words, should be seen as more than the provision of factual representations or pages from a reference manual. It should speak to the personal hands-on experience of performing a task, presented in a manner as close as possible to the original experience.
Allen, J. (2014). Anatomy of a Tweet. Retrieved from Flickr.
Audacity. (2015). README: Please stay on topic. Retrieved from Audacity Forum.
Dash, A. (2007). Cats Can Has Grammar. Retrieved from A Blog About Making Culture: http://dashes.com/anil/2007/04/cats-can-has-gr.html
Ernest, P. (1993). Conversation as Metaphor for Mathematics and Learning. Proceedings of BSRLM Annual Conference, (pp. 58-63). Manchester. Retrieved from http://bsrlm.org.uk/IPs/ip13-3/BSRLM-IP-13-3-13.pdf
Freire, P. (1993). Pedagogy of the Oppressed. New York: Continuum Books. Retrieved from http://www2.webster.edu/~corbetre/philosophy/education/freire/freire-2.html
Gagné, R. M., Briggs, L. J., & Wager, W. W. (1992). Principles of instructional design. Fort Worth: Harcourt Brace Jovanovich. Retrieved from https://canvas.instructure.com/courses/825820/files/29808484/download
Herr, N. (2007). How Experts Differ from Novices. In The Sourcebook for Teaching Science. Jossey-Bass. Retrieved from http://www.csun.edu/science/ref/reasoning/how-students-learn/2.html
Hildreth, P. M., & Kimble, C. (2002). The duality of knowledge. Information Research, 8(1). Retrieved from http://www.informationr.net/ir/8-1/paper142.html
Hogg, A. (2013). Whiteboard it – the power of graph databases. Computer Weekly. Retrieved from http://www.computerweekly.com/feature/Whiteboard-it-the-power-of-graph-databases
Marzi, M. D. (2012). Introduction to Graph Databases. Chicago Graph Database Meetup. Retrieved from http://www.slideshare.net/maxdemarzi/introduction-to-graph-databases-12735789?related=1
McCulloch, G. (2014). A Linguist Explains the Grammar of Doge. Wow. Retrieved from The Toast: http://the-toast.net/2014/02/06/linguist-explains-grammar-doge-wow/
Milekic, S., & Weisler, S. (n.d.). Syntactic Ambiguity. Retrieved from Theory of Language: CD-ROM Edition: http://language-theory.pl/language629.html
Mohammad, S. M., Kiritchenko, S., & Zhu, X. (2013). NRC-Canada: Building the State-of-the-Art in Sentiment Analysis of Tweets. Proceedings of the seventh international workshop on Semantic Evaluation Exercises. Retrieved from http://www.saifmohammad.com/WebDocs/sentimentMKZ.pdf
National Research Council Canada. (2015). Learning and Performance Support Systems. Retrieved from National Research Council Canada: http://www.nrc-cnrc.gc.ca/eng/solutions/collaborative/lpss.html
National Research Council Canada. (2015). Text analytics. Retrieved from National Research Council Canada: http://www.nrc-cnrc.gc.ca/eng/solutions/advisory/text_analytics.html
Neo4J. (2015). What is a Graph Database? Retrieved from Neo4J: http://neo4j.com/developer/graph-database/
Nilsson, N. J. (2007). The Physical Symbol System Hypothesis: Status and prospects. LCNS, 4850. Retrieved from http://ai.stanford.edu/~nilsson/OnlinePubs-Nils/PublishedPapers/pssh.pdf
Roschellel, J., & Teasley, S. D. (1995). The Construction of Shared Knowledge in Collaborative Problem Solving. In C. O. (ed), Computer supported collaborative learning (pp. 69-97). Springer Berlin Heidelberg. Retrieved from http://umdperg.pbworks.com/f/RoschelleTeasley1995OCR.pdf
Stewart, B. (2015). Scholarship in Abundance: Influence, Engagement & Attention in Scholarly Networks. Dissertation Defense. Retrieved from http://www.slideshare.net/bonstewart/scholarship-in-abundance
UNESCO. (2013). What are Open Educational Resources (OERs)? Retrieved from UNESCO: http://www.unesco.org/new/en/communication-and-information/access-to-knowledge/open-educational-resources/what-are-open-educational-resources-oers/
Warmoth, A. (2000). Social Constructionist Epistemology. Retrieved from Sonoma State University: http://www.sonoma.edu/users/w/warmotha/epistemology.html


