Jan 12, 2010
Originally posted on Half an Hour, January 12, 2010.
Summary of a tutorial workshop from Bruce Maggs (Duke University and Akamai).

Services and Design
The basic service to the first customers was the provision of access to static content to websites. For example, cbs.com used Akamai to provide static images for the website. Also, a lot of static objects are delivered to web pages – they don’t appear on web pages. For example, software updates for Microsoft, or virus updates for Symantic. Yahoo uses Akamai to run their DNS service. Apple uses Akamai for realtime streaming of Quicktime. And the FBI uses Akamai to deliver all its content on fbi.gov through Akamai, so there’s no way to access the FBI servers through the site.
Today Akamai has roughly 65,000 servers (was 40,000 servers last summer). There are 1450 points of presence (POPs), 950 networks or ISPs in 67 countries. The first round of servers were typically co-located with ISPs (that’s what OLDaily does too). But that’s expensive; once we got enough traffic we were able to co-locate in universities, ISP, etc to lower the bandwidth coming in. “We’ll serve only your users, but we’re not going to pay for bandwidth, electricity, etc.â€
From 30,000 domains Akamai serves 1.1 terabytes per second, 6,419 terabytes per day. That’s 274 billion hits per day to 274 million unique client addresses per day.
Static Content
The simplest service example occurs when xyz.com decides to outsource its image sourcing. To do this, it may change the URL of its images from www.xyz.com to ak.xyz.com. This results in a domain lookup process that points to the Akamai servers instead of xyz.com’s servers. Image [1] (below) display’s the domain lookup process that happens. In essence, what happens is that the DNS process tells the system that ak.xyz.com is actually a212g.akamai.net (or some such thing, depending on how the load is distributed). These are called ‘domain delegation responses’.

You may wonder how we get better performance by including all these steps. The answer is that they rarely perform all 16 steps. The DNS responses are cached, and the ‘time to live’ tells the servers how long the data will be valid. At the early stages, or for much-used domains, the time-to-live may be a few minutes or even seconds. But the more stable, static time-to-live values may be several days.
So, the system maps the IP address of the client’s name server and the type of content being requested to an Akamai cluster (Akamai has clusters designed for specific types of content, eg., Quicktime video, etc; Akamai also has servers reserved for specific users in a community, eg., at a particular university). Where the content is not served by an ‘Akamai Accelerated Network Partner’ the request is subjected to a more general ‘core point analysis’.
Note that this is based on the name server address, not the client’s address. It assumes that what’s good for the name server is good for the client. Some ISPs were serving all clients from centralized name servers; we’ve asked them not to do this.
What if the user is using a centralized DNS, like Google’s (8.8.8.8)? There’s a system called ‘IPanycast’ – the idea is that while many clients name use the same NS IP address, the reality is that IP address is in many different locations – my request to Google’s server will go to the closest Google NS, but Akamai will get some information about the location of that particular name server (NS).
Now – how does Akamai pick a specific server within a cluster? Remember, the client is mapped to a cluster based on the client’s name server IP address. You need an algorithm to assign clients to specific servers based on specific type of content requested. Algorithms:
- stable marriage with multi-dimensional hierarchy constraints (for load balancing)
- consistent hashing (for content types)
Let’s look first at consistent hashing.
Again, Akamai puts specific types of content on specific servers. The content needs to be spread around the servers, to put the same content type on the same server, and to allocate more server space to more popular (types of) content.
Here’s how the hashing works: you have a set U of web objects, each with a serial number, and you have a set of B buckets, where each bucket is a web server. So the function assigns h:U->B. For example, you might have a random allocation function, h(x)=(((a x+b) mod P) mod |B|), where P is prime and greater than |U|, a and b are chosen randomly, and where x is a serial number.
But this won’t work, because you have a difficulty changing the number of buckets. For example, a server might crash. In consistent hashing, instead of mapping objects directly to buckets, you map both objects and buckets to the unit circle. Then you assign the object to the next bucket in the unit circle. When a bucket is added or subtracted, the only objects affected are the objects mapped to the specific bucket that has changed.
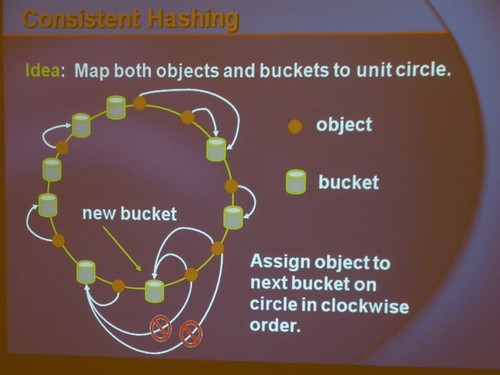
One complication occurs with the use of multiple low-level DNS servers that act independently, since each DNS will have a slightly different view of the hash. The consistent hashing algorithm is sufficiently robust to handle this.
Properties of consistent hashing:
- balance – objects are assigned to buckets random
- monotonicity – when a bucket is added or removed, the only objects affected are those mapped to the bucket
- load – objects are assigned to the buckets evenly over a set of views
- spread – an object is mapped to a small number of buckets over a spread of views
Now, how it’s really done is that each object has a different view of the unit circle. Then it is assigned to the first open server in the circle. They have different views because, if one goes down, you don’t want to assign all the objects to the same new server. Rather, because each view of the unit circle is unique, each is assigned to a (potentially) different server.
Now, what about huge events, such as ‘flash crowds’ (a huge crowd where there is no warning) or planned crowds (such as a software release)? For flash crowds, the system is designed so that, in either case, we don’t do anything. It’s designed to be resilient.
Real-Time Streaming Content
How you pay for bandwidth: typically, you sign a ’95.5 contract’ – you sign a contract saying that ‘as measured at 95.5 percent of usage I’m going to pay so much per megabyte’. But of course many people have less than 95.5 – and you can play games with it, to get the 95.5 number lower (serve some content from elsewhere, eg.). Some huge events change the calculations – big events were 9-11, Steve Jobs keynotes, the Obama inaguration (which doubled the normal peak traffic for the day).
Streaming media has, in the last few years, become the major source of bits that are delivered. Streaming media is becoming viable, it’s happening, but slowly. This is mostly U.S.-based, but there are other locations – Korea, for example. Some sports events have been huge – world cup soccer, NCAA basketball games. The photos below show the network before and after the inauguration (yellow is slow, and red is dead). Everybody’s performance on the internet was degraded (Akamai’s belief is that it’s capacity is as big as the internet’s capacity).
There may be redundant data streaming into clusters, to improve fault-tolerance. The actual serving of the stream is typically through proprietary servers, such as the Quicktime server. Up until the proprietary servers, this is a format-agnostic server system. It just sends data – there is very little error-checking or buffering, because it would create too much of a delay at the client end (eg., for stock market conference calls).
A study from 2004 – 7 percent of streams were video, 71 percent were audio, and 22 percent one or the other (too close to tell by bitrate). There were tons of online radio stations, for example. Streams will often (24 percent of the time) create flash crowds, as shows start, for example. Audio streams (in 2004) often ran 24 hours, but none of the video streams did back then. An analysis of users showed that there was a lot of repeat viewership – the number of new users should go down – but it doesn’t go down very fast. There was a lot of experimenting – people would come and go very quickly. In almost all events, 50 percent of the clients show up one day only and never come back. But if you exclude the one-timers, most people watch for a long time, the full extent of the duration.
What makes for a quality stream? Here are criteria that were used: How often does it fail to start? How long does it take to start? How often does it stop and start up again? You could ask about packet loss, but this is a bit misleading – you have to ask about packets that arrive on time to be used (some packets arrive and are therefore not lost but arrive too late to be useful and are thrown away).
FirstPoint DNS
This is the service that is used to manage the traffic into mirrored websites. It’s a DNS service, eg., for Yahoo. We field the request to send people, eg. To the east coast to the west coast. It directs the browser to the optimal mirror. It may be only two mirrors (which is actually hard to figure out) or as many as 1500. Today, content providers typically want to manage their own servers, and only offload embedded content. This creates a mapping problem: how to direct requests to servers to optimize end-user experience. You want to reduce latency (especially for small objects), reduce loss, and reduce jitter.
So, how do it? We could measure ‘closeness’, but this changes all the time. We could measure latency, frequently. But you get a lot of complaints, and there’s too many clients to ping. What they do: on any given day there are 500,000 distinct name server requests on any given day (not individual web servers, higher level requests; eg., university asks Akamai, where’s Yahoo?). That’s way too many to measure.
There are two major approaches:
First, network topology. This is basically a way of creating a map of the internet. Topologies are relatively static, changing in BGP (border gateway protocol - it’s basically a way of the systems to manage rtoutes, exchanging route information to each other) time.
Second, congestion, This is much more dynamic. You have to measure changes in round-trip time in order of milliseconds. So we do accurate measurements to intermediary point. You don’t measure all the way to the end, because any differences are really out of anyone’s control – we can only control different route to ‘proxy points’ (or ‘core points’). The 500,000 name servers reduce to about 90,000 proxy points. That’s still too many, but at least they’re major routers.
Now if we look at these name servers and sort them according to how many requests we get, if we look at 7,000 of them we are getting 95 percent of all requests from them. So we ping these most often. 30,000 proxy points results in 98.8 percent of every request these are pinged every 6 minutes. We use latency and packet loss to guide the algorithm. We also use other data in mapping – about 800 BGP feeds, traceroute to 1,000,000 per week, constraint-based geolocation, and other data.
SiteShield
There have been attacks that have shut down servers. Siteshield redirects traffic from affected servers. Eg. Yahoo was down once on the east coast, and didn’t know until we told them.
What we want to do is prevent DDOS attacks – this is where the attackers take over innocent user computers (called ‘xombies’) which then launch the attack on the service. Akami basically stands in between the content provider and the attacker – this way the provider’s IP address is shielded, and the attacked server can be swapped out. Akamai has a lot of capacity to handle flash crowds, etc., and so can do the load balancing and can resurrect crashed servers very quickly.
Dealing With Failure
Wherever possible try to build in redundancy, decentralization, self-assessment, fail-over at multiple levels, and robust algorithms.
At the OS level, Akamai started with Red Hat Linux and, over time, have built in Linux performance optimizations and eventually created a ‘secure OS’ derived from 2003 Linux that is ‘battle hardened’. Windows was later added for the Windows content, because Windows Media Server runs on no other platform.
To optimize security on the server: disk and disk cached are managed directly. The network kernel is optimized for short transactions. Services are run in user mode as much as possible. And the only way to get into the machine is through ssh.
Akamai relies a lot on GNU (GPL licensed) software. Akamai only runs the code on its own machines. The license says the act of running the program is not restricted – if you want to distribute the program you have to reveal your own code, but they never do that; they never reveal their own code. (Akamai is close to the line in terms of what they are doing with GPL.)
So what kind of failures are there? Hardware failures, network failures, software failures, configuration failure, misperceptions, and attacks. Of these, configuration failures can be the most severe. Hardware and network you expect to fail, and you build around them. Software can be a problem, because it’s difficult to debug, and it is really easy to get feature creep in your system, so that you’re configuring it in real-time.
Harware can fail for a variety of reasons. The simplest way to respond to it is the buddy system – each server in a cluster is buddied with another. You can also suspend an entire cluster if more than one fails. To recover from a hardware failure, you try to restart, and if it doesn’t work, you replace the server.
Network failures result mostly from congestion and connectivity problems. This was discussed above; it is dealt with basically by pinging the proxy points.
For software, an engineering methodology is adopted, Everything is coded in C, complied with gcc. There is a reliance on open source code. There are large distributed testing systems, and there is an ‘invisible system’ burned in – that is, you try the system without any customers on it to see whether it causes crashes, etc. (it’s sort of like a shadow system, it uses real data, but doesn’t actually serve customers). The rollout is staged – first you start with the ghost shadow system, then to a few customers, then system-wide. The software is always backward-compatible with the previous version. In principle it’s possible to roll back to a previous version, but in practice it’s not a good idea, because you’d have completely clean the server.
But – this, which is state of the art, is still not good enough. It’s still fraught with risk. But there isn’t a better answer yet. There are maybe some long term solutions – safer languages, code you can ‘prove’ is correct, etc. You can prove some things, face the halting problem, but there are some things that are still complex.
Perceived failures – a lot of people see Akamai in their firewalls and think it’s attacking them, because they never requested anything from Akamai. Other misperceptions are created from reporting software, customer-side problems, and third-party measurements (eg. Keynote (http://www.keynote.com), which was swamping servers with too many tests – and now there are servers set up close to keynote for speed measurement, and keynote was told their own servers are overloaded). Or – there was another case where the newspaper’s own internet access was down, and they couldn’t receive Akamai-served content.
Attacks – are usually intended to simply overwhelm a site with too many requests. Hacker-based attacks are usually from individuals. Sometimes there are weird hybrid attacks where volunteers manually click on the websiet (eg. To attack the World Economic Forum (WEF)). Maggs summarized some attacks – the most interesting was a BGP attack, because when the BGP link is broken, they flush all data and reloaded the addresses from scratch, which creates a huge increase in traffic.
War Stories
The Packet of Death – a router in Malaysia was taking servers down. Servers negotiate the ‘maximum sized packet’ that can be sent. But someone had configured a server in Malaysia that chopped servers at some arbitrary number – and the Linux server had a bug that failed on exactly that number. But, of course, every time a server went down, a new server was used – eventually sending every server to that router in Malaysia!
Lost in Space – a server started receiving authenticated but improperly formatted packets from an unknown host. They were being discarded because they were unformatted. It turns out, the ‘attack’ was coming from an old server that had been discarded and was trying to come back into the network. We probably have servers in our rack somewhere that have been running for 10 years that we don’t know about. (Of course, this does raise the question of where you keep your secret data, like keys, if servers can be ‘lost’).
Steve Can’t See the New Powerbook – a certain ‘Steve’ who is very famous had a problem – his assistance Eddie explained that Steve’s new computer can’t see the pictures. Went through the logs, found no evidence he had tried to access the images. Eddie snuck into Steve’s office to try to access the images. No image appeared, no request was sent. Eddie was ‘not allowed’ to tell what OS and browser were being used (Safari on OS X). It turned out that the Akamai urls were so long the web designer put in a line feed. Browsers like Internet Explorer compensate for this, but the new browser didn’t.
David is a Night Owl – one person would start doing experiments at 1:00 a.m. pacific time, and would send a message (at about 4:00 eastern) saying that the servers aren’t responding. But he was using the actual IP address. He asks, “why don’t you support half-closed connectionsâ€. It will be out in two weeks. What about “transactional TCPâ€? We will not support transactional TCP – because it starts and finishes the transaction in a single packet. By sending one packet to a server you can blast data and spoof your source address.
The Magg Syndrome – got a call one day saying Akamai was ‘hijacking’ a website. “I became the most hated person on the internet.†It was when people went to Gomez.com they got the Akamai server, and they would get an Akamai error page. It was a major problem, because Gomez was covering the internet boom and was popular. “We were getting 100,000 requests a day for websites that have nothing to do with us.†First – debrand the website (changed to weberrors.com). Then track where people were trying to go. The number kept going up and up and up. The problem was – when you issue a DNS request to your local server, you provide the name you want resolved, an identifier for your request, and the port where you want to receive the answer. All the problems were happening on one (the most popular) operating system – the operating system wasn’t checking that the name in the answer was the name in the request.
What’s Coming
It’s now possible to run websphere applications on Akamai servers. Most customers, though, depend on a backend database, which is not provided by Akamai. So there needs to be a way to provide database caching at the server level.
Physical security is becoming more of an issue. This is increasing some costs.
There is also the issue of isolation between customer applications (ie., keeping customer applications separate from each other). Akamai is not providing virtual machines, not providing a general purpose plan (so everyone is running under the same server).
Energy management is also an increasing issue. The servers consume more energy than everything else in the company combined. It would be nice to save energy, but that’s difficult, because people are reluctant to turn a server off when it’s idle – it may take time to restart, it may be missing updates, it creates wear and tear on a server (from temperature changes). But even if Akamai can’t save energy, it can save money on energy or use greener sources of energy. Eg. You can switch to servers that are using off-peak energy, etc., or adapt server load to exploit spot-energy prices in the U.S.
Summary of a tutorial workshop from Bruce Maggs (Duke University and Akamai).
Services and Design
The basic service to the first customers was the provision of access to static content to websites. For example, cbs.com used Akamai to provide static images for the website. Also, a lot of static objects are delivered to web pages – they don’t appear on web pages. For example, software updates for Microsoft, or virus updates for Symantic. Yahoo uses Akamai to run their DNS service. Apple uses Akamai for realtime streaming of Quicktime. And the FBI uses Akamai to deliver all its content on fbi.gov through Akamai, so there’s no way to access the FBI servers through the site.
Today Akamai has roughly 65,000 servers (was 40,000 servers last summer). There are 1450 points of presence (POPs), 950 networks or ISPs in 67 countries. The first round of servers were typically co-located with ISPs (that’s what OLDaily does too). But that’s expensive; once we got enough traffic we were able to co-locate in universities, ISP, etc to lower the bandwidth coming in. “We’ll serve only your users, but we’re not going to pay for bandwidth, electricity, etc.â€
From 30,000 domains Akamai serves 1.1 terabytes per second, 6,419 terabytes per day. That’s 274 billion hits per day to 274 million unique client addresses per day.
Static Content
The simplest service example occurs when xyz.com decides to outsource its image sourcing. To do this, it may change the URL of its images from www.xyz.com to ak.xyz.com. This results in a domain lookup process that points to the Akamai servers instead of xyz.com’s servers. Image [1] (below) display’s the domain lookup process that happens. In essence, what happens is that the DNS process tells the system that ak.xyz.com is actually a212g.akamai.net (or some such thing, depending on how the load is distributed). These are called ‘domain delegation responses’.
You may wonder how we get better performance by including all these steps. The answer is that they rarely perform all 16 steps. The DNS responses are cached, and the ‘time to live’ tells the servers how long the data will be valid. At the early stages, or for much-used domains, the time-to-live may be a few minutes or even seconds. But the more stable, static time-to-live values may be several days.
So, the system maps the IP address of the client’s name server and the type of content being requested to an Akamai cluster (Akamai has clusters designed for specific types of content, eg., Quicktime video, etc; Akamai also has servers reserved for specific users in a community, eg., at a particular university). Where the content is not served by an ‘Akamai Accelerated Network Partner’ the request is subjected to a more general ‘core point analysis’.
Note that this is based on the name server address, not the client’s address. It assumes that what’s good for the name server is good for the client. Some ISPs were serving all clients from centralized name servers; we’ve asked them not to do this.
What if the user is using a centralized DNS, like Google’s (8.8.8.8)? There’s a system called ‘IPanycast’ – the idea is that while many clients name use the same NS IP address, the reality is that IP address is in many different locations – my request to Google’s server will go to the closest Google NS, but Akamai will get some information about the location of that particular name server (NS).
Now – how does Akamai pick a specific server within a cluster? Remember, the client is mapped to a cluster based on the client’s name server IP address. You need an algorithm to assign clients to specific servers based on specific type of content requested. Algorithms:
- stable marriage with multi-dimensional hierarchy constraints (for load balancing)
- consistent hashing (for content types)
Let’s look first at consistent hashing.
Again, Akamai puts specific types of content on specific servers. The content needs to be spread around the servers, to put the same content type on the same server, and to allocate more server space to more popular (types of) content.
Here’s how the hashing works: you have a set U of web objects, each with a serial number, and you have a set of B buckets, where each bucket is a web server. So the function assigns h:U->B. For example, you might have a random allocation function, h(x)=(((a x+b) mod P) mod |B|), where P is prime and greater than |U|, a and b are chosen randomly, and where x is a serial number.
But this won’t work, because you have a difficulty changing the number of buckets. For example, a server might crash. In consistent hashing, instead of mapping objects directly to buckets, you map both objects and buckets to the unit circle. Then you assign the object to the next bucket in the unit circle. When a bucket is added or subtracted, the only objects affected are the objects mapped to the specific bucket that has changed.
One complication occurs with the use of multiple low-level DNS servers that act independently, since each DNS will have a slightly different view of the hash. The consistent hashing algorithm is sufficiently robust to handle this.
Properties of consistent hashing:
- balance – objects are assigned to buckets random
- monotonicity – when a bucket is added or removed, the only objects affected are those mapped to the bucket
- load – objects are assigned to the buckets evenly over a set of views
- spread – an object is mapped to a small number of buckets over a spread of views
Now, how it’s really done is that each object has a different view of the unit circle. Then it is assigned to the first open server in the circle. They have different views because, if one goes down, you don’t want to assign all the objects to the same new server. Rather, because each view of the unit circle is unique, each is assigned to a (potentially) different server.
Now, what about huge events, such as ‘flash crowds’ (a huge crowd where there is no warning) or planned crowds (such as a software release)? For flash crowds, the system is designed so that, in either case, we don’t do anything. It’s designed to be resilient.
Real-Time Streaming Content
How you pay for bandwidth: typically, you sign a ’95.5 contract’ – you sign a contract saying that ‘as measured at 95.5 percent of usage I’m going to pay so much per megabyte’. But of course many people have less than 95.5 – and you can play games with it, to get the 95.5 number lower (serve some content from elsewhere, eg.). Some huge events change the calculations – big events were 9-11, Steve Jobs keynotes, the Obama inaguration (which doubled the normal peak traffic for the day).
Streaming media has, in the last few years, become the major source of bits that are delivered. Streaming media is becoming viable, it’s happening, but slowly. This is mostly U.S.-based, but there are other locations – Korea, for example. Some sports events have been huge – world cup soccer, NCAA basketball games. The photos below show the network before and after the inauguration (yellow is slow, and red is dead). Everybody’s performance on the internet was degraded (Akamai’s belief is that it’s capacity is as big as the internet’s capacity).
There may be redundant data streaming into clusters, to improve fault-tolerance. The actual serving of the stream is typically through proprietary servers, such as the Quicktime server. Up until the proprietary servers, this is a format-agnostic server system. It just sends data – there is very little error-checking or buffering, because it would create too much of a delay at the client end (eg., for stock market conference calls).
A study from 2004 – 7 percent of streams were video, 71 percent were audio, and 22 percent one or the other (too close to tell by bitrate). There were tons of online radio stations, for example. Streams will often (24 percent of the time) create flash crowds, as shows start, for example. Audio streams (in 2004) often ran 24 hours, but none of the video streams did back then. An analysis of users showed that there was a lot of repeat viewership – the number of new users should go down – but it doesn’t go down very fast. There was a lot of experimenting – people would come and go very quickly. In almost all events, 50 percent of the clients show up one day only and never come back. But if you exclude the one-timers, most people watch for a long time, the full extent of the duration.
What makes for a quality stream? Here are criteria that were used: How often does it fail to start? How long does it take to start? How often does it stop and start up again? You could ask about packet loss, but this is a bit misleading – you have to ask about packets that arrive on time to be used (some packets arrive and are therefore not lost but arrive too late to be useful and are thrown away).
FirstPoint DNS
This is the service that is used to manage the traffic into mirrored websites. It’s a DNS service, eg., for Yahoo. We field the request to send people, eg. To the east coast to the west coast. It directs the browser to the optimal mirror. It may be only two mirrors (which is actually hard to figure out) or as many as 1500. Today, content providers typically want to manage their own servers, and only offload embedded content. This creates a mapping problem: how to direct requests to servers to optimize end-user experience. You want to reduce latency (especially for small objects), reduce loss, and reduce jitter.
So, how do it? We could measure ‘closeness’, but this changes all the time. We could measure latency, frequently. But you get a lot of complaints, and there’s too many clients to ping. What they do: on any given day there are 500,000 distinct name server requests on any given day (not individual web servers, higher level requests; eg., university asks Akamai, where’s Yahoo?). That’s way too many to measure.
There are two major approaches:
First, network topology. This is basically a way of creating a map of the internet. Topologies are relatively static, changing in BGP (border gateway protocol - it’s basically a way of the systems to manage rtoutes, exchanging route information to each other) time.
Second, congestion, This is much more dynamic. You have to measure changes in round-trip time in order of milliseconds. So we do accurate measurements to intermediary point. You don’t measure all the way to the end, because any differences are really out of anyone’s control – we can only control different route to ‘proxy points’ (or ‘core points’). The 500,000 name servers reduce to about 90,000 proxy points. That’s still too many, but at least they’re major routers.
Now if we look at these name servers and sort them according to how many requests we get, if we look at 7,000 of them we are getting 95 percent of all requests from them. So we ping these most often. 30,000 proxy points results in 98.8 percent of every request these are pinged every 6 minutes. We use latency and packet loss to guide the algorithm. We also use other data in mapping – about 800 BGP feeds, traceroute to 1,000,000 per week, constraint-based geolocation, and other data.
SiteShield
There have been attacks that have shut down servers. Siteshield redirects traffic from affected servers. Eg. Yahoo was down once on the east coast, and didn’t know until we told them.
What we want to do is prevent DDOS attacks – this is where the attackers take over innocent user computers (called ‘xombies’) which then launch the attack on the service. Akami basically stands in between the content provider and the attacker – this way the provider’s IP address is shielded, and the attacked server can be swapped out. Akamai has a lot of capacity to handle flash crowds, etc., and so can do the load balancing and can resurrect crashed servers very quickly.
Dealing With Failure
Wherever possible try to build in redundancy, decentralization, self-assessment, fail-over at multiple levels, and robust algorithms.
At the OS level, Akamai started with Red Hat Linux and, over time, have built in Linux performance optimizations and eventually created a ‘secure OS’ derived from 2003 Linux that is ‘battle hardened’. Windows was later added for the Windows content, because Windows Media Server runs on no other platform.
To optimize security on the server: disk and disk cached are managed directly. The network kernel is optimized for short transactions. Services are run in user mode as much as possible. And the only way to get into the machine is through ssh.
Akamai relies a lot on GNU (GPL licensed) software. Akamai only runs the code on its own machines. The license says the act of running the program is not restricted – if you want to distribute the program you have to reveal your own code, but they never do that; they never reveal their own code. (Akamai is close to the line in terms of what they are doing with GPL.)
So what kind of failures are there? Hardware failures, network failures, software failures, configuration failure, misperceptions, and attacks. Of these, configuration failures can be the most severe. Hardware and network you expect to fail, and you build around them. Software can be a problem, because it’s difficult to debug, and it is really easy to get feature creep in your system, so that you’re configuring it in real-time.
Harware can fail for a variety of reasons. The simplest way to respond to it is the buddy system – each server in a cluster is buddied with another. You can also suspend an entire cluster if more than one fails. To recover from a hardware failure, you try to restart, and if it doesn’t work, you replace the server.
Network failures result mostly from congestion and connectivity problems. This was discussed above; it is dealt with basically by pinging the proxy points.
For software, an engineering methodology is adopted, Everything is coded in C, complied with gcc. There is a reliance on open source code. There are large distributed testing systems, and there is an ‘invisible system’ burned in – that is, you try the system without any customers on it to see whether it causes crashes, etc. (it’s sort of like a shadow system, it uses real data, but doesn’t actually serve customers). The rollout is staged – first you start with the ghost shadow system, then to a few customers, then system-wide. The software is always backward-compatible with the previous version. In principle it’s possible to roll back to a previous version, but in practice it’s not a good idea, because you’d have completely clean the server.
But – this, which is state of the art, is still not good enough. It’s still fraught with risk. But there isn’t a better answer yet. There are maybe some long term solutions – safer languages, code you can ‘prove’ is correct, etc. You can prove some things, face the halting problem, but there are some things that are still complex.
Perceived failures – a lot of people see Akamai in their firewalls and think it’s attacking them, because they never requested anything from Akamai. Other misperceptions are created from reporting software, customer-side problems, and third-party measurements (eg. Keynote (http://www.keynote.com), which was swamping servers with too many tests – and now there are servers set up close to keynote for speed measurement, and keynote was told their own servers are overloaded). Or – there was another case where the newspaper’s own internet access was down, and they couldn’t receive Akamai-served content.
Attacks – are usually intended to simply overwhelm a site with too many requests. Hacker-based attacks are usually from individuals. Sometimes there are weird hybrid attacks where volunteers manually click on the websiet (eg. To attack the World Economic Forum (WEF)). Maggs summarized some attacks – the most interesting was a BGP attack, because when the BGP link is broken, they flush all data and reloaded the addresses from scratch, which creates a huge increase in traffic.
War Stories
The Packet of Death – a router in Malaysia was taking servers down. Servers negotiate the ‘maximum sized packet’ that can be sent. But someone had configured a server in Malaysia that chopped servers at some arbitrary number – and the Linux server had a bug that failed on exactly that number. But, of course, every time a server went down, a new server was used – eventually sending every server to that router in Malaysia!
Lost in Space – a server started receiving authenticated but improperly formatted packets from an unknown host. They were being discarded because they were unformatted. It turns out, the ‘attack’ was coming from an old server that had been discarded and was trying to come back into the network. We probably have servers in our rack somewhere that have been running for 10 years that we don’t know about. (Of course, this does raise the question of where you keep your secret data, like keys, if servers can be ‘lost’).
Steve Can’t See the New Powerbook – a certain ‘Steve’ who is very famous had a problem – his assistance Eddie explained that Steve’s new computer can’t see the pictures. Went through the logs, found no evidence he had tried to access the images. Eddie snuck into Steve’s office to try to access the images. No image appeared, no request was sent. Eddie was ‘not allowed’ to tell what OS and browser were being used (Safari on OS X). It turned out that the Akamai urls were so long the web designer put in a line feed. Browsers like Internet Explorer compensate for this, but the new browser didn’t.
David is a Night Owl – one person would start doing experiments at 1:00 a.m. pacific time, and would send a message (at about 4:00 eastern) saying that the servers aren’t responding. But he was using the actual IP address. He asks, “why don’t you support half-closed connectionsâ€. It will be out in two weeks. What about “transactional TCPâ€? We will not support transactional TCP – because it starts and finishes the transaction in a single packet. By sending one packet to a server you can blast data and spoof your source address.
The Magg Syndrome – got a call one day saying Akamai was ‘hijacking’ a website. “I became the most hated person on the internet.†It was when people went to Gomez.com they got the Akamai server, and they would get an Akamai error page. It was a major problem, because Gomez was covering the internet boom and was popular. “We were getting 100,000 requests a day for websites that have nothing to do with us.†First – debrand the website (changed to weberrors.com). Then track where people were trying to go. The number kept going up and up and up. The problem was – when you issue a DNS request to your local server, you provide the name you want resolved, an identifier for your request, and the port where you want to receive the answer. All the problems were happening on one (the most popular) operating system – the operating system wasn’t checking that the name in the answer was the name in the request.
What’s Coming
It’s now possible to run websphere applications on Akamai servers. Most customers, though, depend on a backend database, which is not provided by Akamai. So there needs to be a way to provide database caching at the server level.
Physical security is becoming more of an issue. This is increasing some costs.
There is also the issue of isolation between customer applications (ie., keeping customer applications separate from each other). Akamai is not providing virtual machines, not providing a general purpose plan (so everyone is running under the same server).
Energy management is also an increasing issue. The servers consume more energy than everything else in the company combined. It would be nice to save energy, but that’s difficult, because people are reluctant to turn a server off when it’s idle – it may take time to restart, it may be missing updates, it creates wear and tear on a server (from temperature changes). But even if Akamai can’t save energy, it can save money on energy or use greener sources of energy. Eg. You can switch to servers that are using off-peak energy, etc., or adapt server load to exploit spot-energy prices in the U.S.


