I’m excited to be teaching Stanford Law’s first Coursera offering this fall, on government surveillance. In preparation, I’ve been extensively poking around the platform; while I found some snazzy features, I also stumbled across a few security and privacy issues.
- Any teacher can dump the entire user database, including over nine million names and email addresses.
- If you are logged into your Coursera account, any website that you visit can list your course enrollments.
- Coursera’s privacy-protecting user IDs don’t do much privacy protecting.
The balance of this piece provides some detail on each of the vulnerabilities.
Update 9/4: Coursera has acknowledged the issues, and claims they are “fully addressed.” The second vulnerability, however, still exists.
Update 9/6: Coursera appears to have imposed rate limiting on the APIs associated with the second vulnerability, mitigating the risk to users. A malicious website can now iterate over about 10% of the course catalog before having to wait.

1. Downloading Coursera’s User Database
Several of Coursera’s teacher pages include a user autocomplete field.
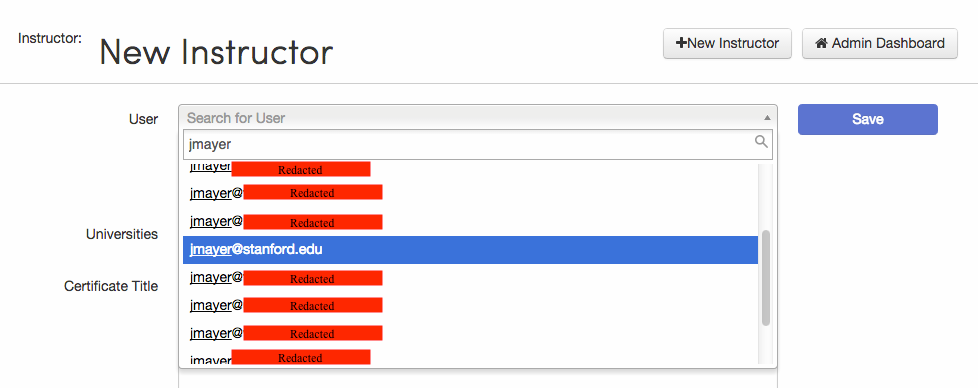
Example autocomplete field, for creating a new instructor.
After typing a few characters from a user’s email address, a drop down makes suggestions. That was an immediate red flag, since autocomplete is usually based on information that a user can already access. Webmail autocomplete, for example, relies on previous messages; social network autocomplete relies on a public directory.
Autocomplete with semi-private information is inherently risky: it’s easy to inadvertently share too much. A similar vulnerability in AT&T’s iPad registration website, for example, enabled Daniel Spitler and Andrew “weev” Auernheimer to dump subscriber email addresses. (The two were subsequently prosecuted. Jennifer Granick and I coauthored an amicus brief in Auernheimer’s appeal, arguing that he hadn’t violated the federal hacking law.)
Back to Coursera. The email autocomplete, I noticed, uses a simple API endpoint. A request for
http://www.coursera.org/maestro/api/admin/search?email=jm
returns something like
[...,
{
"auth_type": 0,
"display_email": "jmayer@...",
"id": 544426,
"full_name": "Jonathan Mayer",
"email": "jmayer@..."
}, ...
]
It’s also possible to query the API using Coursera’s sequential (“internal”) user IDs.
https://www.coursera.org/maestro/api/admin/search?id=544426
Since the API does not have any rate limiting in place, anyone with teacher access could trivially iterate over user IDs or email substrings and dump the entire database. As a proof of concept, I cobbled together the following JavaScript. It fetches 1,000 user names and email addresses.
var users = [];
var startID = 1;
var stopID = 1000;
for (var i = startID; i <= stopID; i++) {
var req = new XMLHttpRequest();
req.onload = function() {
try {
data = JSON.parse(req.responseText);
if (data.length > 0) users.push(data[0]);
} catch (e) {}
};
req.open("get", "https://www.coursera.org/maestro/api/admin/search?id=" + i, false);
req.send();
}
Yes, it works.
I reported this issue to Coursera last Thursday; to the company’s credit, in less than a day API responses were reduced to 10 records (down from 200) and email queries required 5 characters (up from 2). Rate limits—the most important defense, if Coursera retains this autocomplete feature—will also be enabled soon. So, the good news is that dumping the entire student database will become much more difficult.
The bad news is that anyone with teacher access can still look up any individual student’s contact information, so long as he or she either knows the student’s internal ID (it’s embedded in many pages) or can guess a distinctive part of the student’s email address (maybe try first initial last name?). That’s a questionable security model, and it’s potentially inconsistent with Coursera’s privacy policy.1
2. Listing a Student’s Course Enrollments
Educational choices can be very revealing. A quick skim of Coursera’s catalog, for instance, turns up offerings related to medical conditions and religious beliefs. The notion that course enrollments should be (optionally) private is certainly not new—for over forty years, federal law has limited when academic institutions can share student records.2
While fiddling with Coursera’s APIs, I spotted a cross-origin information leak that could be used to list a student’s course enrollments. The idea is that certain endpoints respond to user permission problems with an HTTP error status. Another website could trivially trigger a request to those endpoints and check the response status.
Consider the user ID endpoint at
https://api.coursera.org/utilities/v1/whoami
If a user is not logged in, the response reads like
{"message":"unauthorized"}
with a 401 Unauthorized status. By contrast, if the user is logged in, the response is like
{"userId":"544426","partnerId":"None","isCoursera":"true"}
with a 200 OK status. It’s easy for another website to determine whether a user is logged in, like so
<script onload="userIsLoggedIn()" onerror="userIsNotLoggedIn()" src="https://api.coursera.org/utilities/v1/whoami" type="text/javascript"></script>
The very same approach works for listing a student’s courses. The endpoint at
https://api.coursera.org/api/sessions/v1/COURSE_ID/sections/1/items
returns materials for the first section of a course. If a student is enrolled, 200 OK; if not, 401 Unauthorized.
Developing a proof-of-concept was straightforward. If you’d like to see the issue in action, log into your Coursera account and visit this test page. With near-zero effort at optimization, the page gathers your course enrollments in under a minute.
I reported the issue to Coursera on Sunday, and I have not yet received a response. Possible remediation steps include rate limiting (again), referrer checking, and configuring APIs to always return the same HTTP status.
3. Undoing User ID Privacy Protection
Every user in Coursera’s system has two separate identifiers: a sequential “internal” ID, and a gibberish-looking “external” ID. My internal ID, for example, is 544426 and my external ID is fe7e73fef0333f550378979caa1d3347.
The reason for maintaining two identifiers is, supposedly, account security and privacy. A public resource, such as a user profile page, references just the external ID.
https://www.coursera.org/user/i/fe7e73fef0333f550378979caa1d3347
It is difficult to discern what, exactly, the dual ID scheme is supposed to accomplish. So long as a user’s profile is accessible, one API endpoint at
https://www.coursera.org/maestro/api/user/profiles
maps the internal ID to the external ID.
[{
...
"external_id": "fe7e73fef0333f550378979caa1d3347"
}]
Another API endpoint, at
https://www.coursera.org/maestro/api/user/profile
maps the external ID to the internal ID.
{
...
"id": 544426,
...
}
It’s trivial to undo any (mysterious) security or privacy gain so long as these APIs are available. It’s also trivial to build a dictionary of internal and external IDs.
What’s more, most external IDs aren’t actually gibberish. They appear to fall into three sets:
- For users with internal IDs roughly between 0 and 1.15M, the external ID is simply an MD5 hash of some (relatively) small number. My external ID, for example, is the hash of 315368.
- For users with internal IDs roughly between 1.15M and 7M, the external ID is merely an MD5 hash of the internal ID.
- For users with internal IDs of 7M or above, the external ID is not super-obviously reversible.
The punchline is that, for the majority of Coursera users, no API is even needed to flip between external and internal IDs. If you’re curious about your own external ID, you can grab it from your Coursera profile URL and pop it into a free MD5 reversal website.
I notified Coursera of this issue last Thursday. Apparently external IDs for new users haven’t been generated with MD5 for about a year. That prospectively solves one aspect of the problem—but it doesn’t address older (i.e. most) users or the mapping APIs.
Most importantly, it doesn’t explain what these external IDs are supposed to achieve. Even if there were no simple APIs for mapping IDs, and even if external IDs weren’t easily reversible (e.g. a salted hash or HMAC), what is the precise security or privacy benefit?
1. Coursera’s privacy policy lists circumstances in which a student’s contact information might be shared with an academic institution, including when a student has enrolled in one of the institution’s courses and for marketing purposes. Those caveats would not seem to cover making every student’s information available to every teacher.
2. Coursera and partner institutions have taken the position that offerings on the platform are not covered by the Family Educational Rights and Privacy Act (FERPA). Online courses do not have “students,” they have “participants.”